Eccomi qua a raccontare l'esperienza nella traduzione di giochi AGI.
Questo sistema di sviluppo di videogiochi è più complicato dello SCI, perché non usa la classica interfaccia punta-e-clicca ma un parser testuale; in pratica vanno tradotte le frasi scritte dal giocatore selezionando i
token (verbi, sostantivi).
Però non scoraggiatevi, prodi aspiranti traduttori: nulla è impossibile, armiamoci e partiamo!:yes:
Abbiamo tre fasi nel processo di traduzione: i dialoghi che appaiono a video, i vocaboli contenuti nel dizionario del gioco (nel file words.tok) e le descrizioni degli oggetti (quasi sempre non influente). Non esiste un ordine migliore di un altro, ognuno potrà procedere nel modo che trova più congeniale. In questa guida vi illustrerò il sistema che ho trovato più utile per evitare errori.
Diamo ora uno sguardo alle utility adatte allo scopo:
WINagi (
http://agiwiki.sierrahelp.com/index.php?title=WinAGI) ancora aggiornato
AGIstudio (
http://agi.sierrahelp.com/IDEs/AGIStudio.html) abbandonato dal 2002
Consiglio di provarle entrambe e di sceglierne una a seconda dellapproccio che volete dare alla traduzione. Entrambe hanno pregi e difetti. Se puntate alla semplice conversione del testo scritto, andate sul più vecchio agistudio; se volete mettere mano alle immagini e sistemare eventuali bug del gioco, andate su winagi.
Per chiarire le differenze, vediamo il comportamento con i files di Kings Quest 2. I dialoghi sono contenuti negli
script del gioco, che sono una serie di procedure (routine) scritte in linguaggio C . Quando il
parser ha analizzato la frase scritta dallutente e ha estrapolato i
token corrispondenti (le parole chiave utili al programma), le passa alla routine presente nello
script che le controlla e scrive a video le frasi corrispondenti. Bene, con agistudio si riesce ad estrarre tutti gli script del gioco, e a ricompilarli una volta finita la traduzione. Con winagi vengono segnalati diversi errori dopo lestrazione perché il programma analizza il codice e riporta utilizzi non corretti di variabili nelle routine (e questo nonostante la versione del gioco sia la 2.2 e funzioni senza crash, a dimostrazione che troppi ritocchi creano qualche bug

). In compenso, quando poi ricompilate il file, verifica la presenza dei vocaboli tradotti nel dizionario del gioco.

Ora però cominciamo da zero utilizzando agistudio e puntando su Kings Quest 2. Selezionate la cartella in cui è contenuto il gioco. Verrà caricata una finestra che offre lanteprima dei vari elementi (i tipi di elementi modificabili sono logic, picture, view, sound). Lutility creerà in automatico la cartella SRC allinterno della cartella del gioco, dove salverà i file decompressi.
Cambiate la scritta della casella di riepilogo da VIEW a LOGIC :
Cliccando una volta su LOGIC.000 vedrete lanteprima dello
script, mentre cliccando due volte agistudio decomprimerà il file per consentirvi la modifica (tra poco vedremo come). Le frasi visualizzate dal gioco sono contenute nei comandi
print, mentre le parole chiave che lutente dovrà digitare durante il gioco sono contenute nei comandi
said.
Per trovare il modo migliore di procedere bisogna capire come funziona lestrazione degli script. I vocaboli usati dal gioco nei comandi
said sono parametrizzati, agistudio sostituisce durante la decompressione dello
script il numero usato dal gioco con il vocabolo presente nel dizionario. Traducendo subito i vocaboli del dizionario si può incappare in errori. Per esempio, in KQ2 avevo tradotto la parola SHOW con SPETTACOLO perché ritenevo fosse un sostantivo, e tradurlo con MOSTRA non mi piaceva, ma dopo aver trovato SHOW dentro vari comandi
said ho capito che si trattava di un verbo e lho ri-modificato in MOSTRA.
Quindi vi consiglio di
non estrarre tutti i logic subito, ma di guardarli velocemente in anteprima (finestra preview) tenendo aperto il file WORDS.TOK e la finestra object editor, come da esempio qui sotto. Procedete alla traduzione delle parole in WORDS.TOK , tenendo presente che nei comandi
said viene prima il verbo e poi il sostantivo. Fate attenzione agli oggetti presenti nel gioco: dovete usare lo stesso termine anche nella finestra object editor.
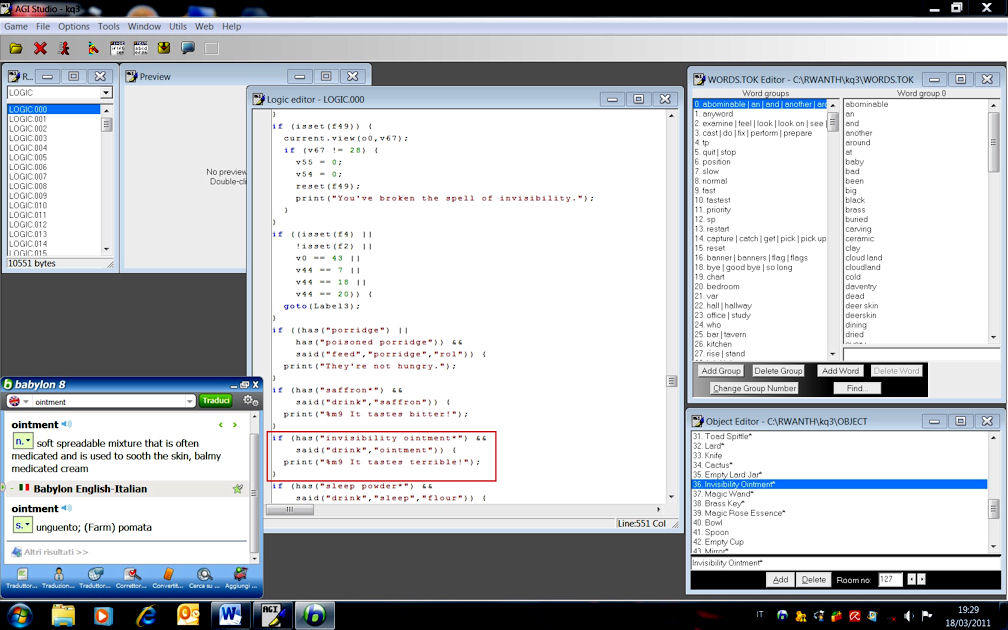
immagine ingrandita:
clicca quiUna volta completata questa fase, si può estrarre e tradurre i logic. In questo modo il lavoro sarà facilitato dal momento che le parole chiave saranno già in italiano e capirete meglio il senso dei dialoghi. Prendiamo ad esempio la videata qui sopra. Modificando la parola examine nel gruppo n.2 del dizionario con esamina, ogni volta che aprirete uno script che usa quel vocabolo, nella finestra di agistudio non troverete questo comando:
if said(examine) ...ma questo:
if said(esamina) ...Proseguiamo ad analizzare il comando evidenziato dal riquadro rosso nell'esempio qui sopra. Quel codice verifica che il protagonista abbia lunguento dellinvisibilità e - nel caso il giocatore scriva bevi unguento - il gioco risponde unguento ha un sapore terribile!.
Attenzione a non usare il carattere apice nelle parole del dizionario tradotte in italiano, p.es.
lunguento, perché viene considerata una parola intera. Bisogna essere telegrafici, sia quando si traduce sia quando si gioca. Per il motivo opposto cercate di non usare due parole per tradurne una. Un esempio tipico:
about tradotto con
riguardo a , perché il
parser scarta la A e non trova la sola parola "riguardo"; non tradurre
about nemmeno con
di o
su perché verrebbero ignorati. Di solito si usa "circa".
Ed ora una spiegazione sulla finestra WORDS.TOK. Cercherò di rendere lidea di come funziona.
Nella parte sinistra si trova la lista dei gruppi di vocaboli trattati dal gioco; i gruppi possono essere costituiti da una sola parola o da diverse parole. In questultimo caso, tutte le parole dello stesso gruppo vengono trattate come sinonimi, anche se hanno un significato molto diverso tra di loro. Per il gioco sono equivalenti.
Esiste un gruppo che ha un significato particolare: il gruppo zero. Le parole contenute nel gruppo zero vengono viste dal
parser come facenti parte del gioco, ma vengono ignorate e mai passate allo
script, perché non sono
token (parole chiave). La domanda sorge spontanea: perché esiste questo gruppo? Qualsiasi parola scritta dallutente senza significato verrebbe scartata, per esempio una parola con errori di ortografia. Secondo me serve al
parser per individuare i
token corretti. Guardando lo screenshot sopra, la prima parola inutile è
abominevole. Nel gruppo 301 cè
snowman (uomo delle nevi) e
yeti. Individuare laggettivo associato al nome aiuta il
parser a scegliere nella frase scritta dallutente il verbo e il nome corretto da passare allo
script, quindi... va tradotto anche il gruppo zero!
Fate attenzione a non tradurre la parola ANYWORD perché è come un jolly, qualsiasi frase scritta andrà bene per lo
script.
Altra cosa da tenere presente: non modificare lordine delle parole e non aggiungere gruppi di parole. Il gioco ha già le sue regole, non ne state facendo uno da zero, lui verifica i vocaboli a seconda della posizione. Per esempio la parola
office sta nel gruppo 23 e là deve rimanere. Lo
script che risponde al comando "esamina ufficio" va a verificare se nella frase digitata cè il vocabolo 23 e lì non potete certo metterci la parola
abominevole, giusto?
Ultima nota: ci si può semplificare il lavoro usando traduttori automatici online e poi ritoccando le frasi tradotte, basta selezionare la frase in agistudio e premere una specifica combinazione di tasti. Due esempi:
DeepL e
Reverso , oltre al famoso Babylon.
Bene, non mi resta che salutarvi.

Scrivete per qualunque chiarimento.

