Approfittando della frescura di un temporale estivo, eccomi qui col pc acceso a disquisire sull'algoritmo LZSS.
Non è granché utilizzato, si trova in pochissimi giochi, ma è alla base di tutti i più famosi programmi di compressione, perciò vale la pena esaminarlo.
[AGGIORNAMENTO AL 23/03/14] Cercherò di spiegarvi come funziona la decompressione, il meccanismo della compressione non mi è ancora del tutto chiaro.
Partiamo subito con le immagini, poi le spiegazioni.
La prima scritta del gioco: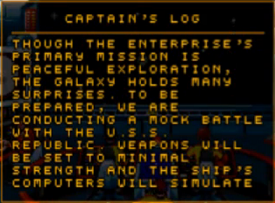 Il contenuto di DATA.DIR:
Il contenuto di DATA.DIR: Il contenuto di DATA.001:
Il contenuto di DATA.001: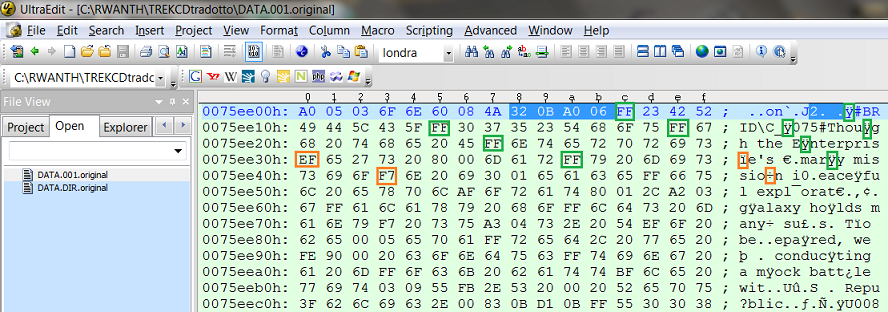
DATA.DIR contiene i nomi dei files compressi e la posizione in cui si trovano all'interno dell'archivio (
offset).
DATA.001 contiene i files compressi, ognuno ha una intestazione di 4 byte che indica la dimensione originale non compressa (primi due) e quella compressa (ultimi due).
Innanzitutto bisogna decomprimere l'archivio DATA.001. Ho usato
TREK2EXT e ne ha estratti NOVEMILA !!!
I file contenenti i testi sono suddivisi in due tipi: quelli dei dialoghi a bordo dell'Enterprise hanno estensione TXT e DB, quelli con i dialoghi nei pianeti (i più importanti) hanno estensione RDF e sono un misto di codice esadecimale e frasi.
La frase riportata nelle immagini qui sopra si trova in DEMON.TXT. Osservando il DATA.DIR si nota che i nomi hanno la classica lunghezza fissa del DOS di 8 caratteri + 3 di estensione, senza il punto separatore e con il codice hex
00 per indicare uno spazio vuoto. Ho evidenziato il file in questione e l'offset da cui inizia il testo dentro DATA.001, cioé
08 EE 75; bene andiamo a cercare quella posizione nel DATA.001 ... qualcosa non torna, vero?
In effetti il codice del gioco estrae in
runtime i vari files, quindi "ragiona" in codice binario: da destra a sinistra. Invertiamo i tre byte ed ecco trovato l'indirizzo che ci serve:
75 EE 08 !
Guardiamo cosa si trova nel demon.txt a quell'indirizzo. La terza immagine ne evidenzia i primi 4 byte :
32 0B A0 06.
I primi due sono la dimensione del file su disco:
32 0B che invertiti diventano
0B 32 corrispondenti in decimale a
2866 byte. Con esplora risorse clicchiamo col tasto destro sul file e scegliamo proprietà: ci siamo!
A0 06 sono invece la dimensione del file compresso, invertendo diventa
06 A0 che in decimale fa 1696 byte. Serve a calcolare l'indirizzo di fine file per sapere quando fermarci.
Segue il testo. L'algoritmo LZSS comprime i caratteri a gruppi di 8 e inserisce un byte all'inizio della stringa che indica SE e quanto è compressa (vedremo poi come). Se non viene compresso nulla il flag ha valore
FF. Ho evidenziato alcuni di essi per chiarire il funzionamento.
Ora possiamo:
- tradurre i file TXT, DB e RDF
- convertire in esadecimale la dimensione dei file tradotti e annotarla
- inserire il byte
FF ogni 8 caratteri
- convertire la nuova dimensione e annotarla (sarà maggiore e non compressa, ma la velocità di calcolo dei pc attuali non porterà a rallentamenti)
- aggiungere i TXT, DB e RDF "compressi" in fondo al DATA.001, sostituendo nel DATA.DIR l'offset (invertito).
A proposito del data.dir, c'è una funzione MULTIFILES al suo interno, non l'ho trovata descritta in nessun sito perciò penso sia una personalizzazione fatta apposta per la Interplay. Si tratta di una compressione dell'indice, in pratica quando c'è una sequenza di file con numeri consecutivi viene memorizzato solo il nome del primo file e l'offset è settato con un codice particolare.
Confrontiamo due esempi: FILE000.DB ---> FILE009.DB (totale
10 files), FILE180.DB ---> FILE181.DB (totale
2 files)
Nel DATA.DIR troviamo i seguenti offset per le due serie sopra citate:
8A 32 7A
82 33 F4Non sono indirizzi presenti nell'archivio perché la sua dimensione non arriva a questi valori; il primo byte è un flag e funziona così:
8A in binario --->
1000 101082 in binario --->
1000 0010il bit più alto (quello più a sinistra) se impostato a 1 indica la presenza di una sequenza di files;
il semi-byte più basso indica quanti sono i file concatenati dentro DATA.001 (
1010 in decimale -->
10,
0010 -->
2)
quindi la domanda è :
qual è l'offset? Cioè : dove si trovano nel data.001? Togliendo i valori 8A e 82 restano due byte per ciascuna sequenza, troppo pochi mannaggia!
Comunque andando per esclusione si trovano e si possono salvare anche separatamente, "in chiaro", aggiungendo i nomi in fondo al DATA.DIR. L'unico problema è che in questo modo le dimensioni del DATA.001 aumentano e il gioco non decomprime oltre un certo valore.
Ok, ora siamo in grado di estrarre in un nuovo file tutte le sequenze di 8 byte dopo il codice
FF semplicemente copiandole così come sono (nell'esempio arriviamo a
though the enterpris), ma come fare per quelle compresse, tipo la sequenza dopo
EF?
LZSS usa un dizionario di 5 sequenze di 3 lettere e lo gestisce con la tecnica FIFO. In breve: ci sono parole in memoria che vengono sostituite da puntatori di due byte.
Il valore binario di
EF è 111
0 1111 quindi leggendo da destra a sinistra un solo byte è compresso, il quinto. Là troviamo due caratteri
. che corrispondono all'hex
80 00, invertiamo in
0080, in decimale fa 128 che diviso 16 (non so ancora perché) fa 8. Torniamo indietro dalla posizione attuale (
) di 8 caratteri e troviamo la
p della parola
Enterprise, prendiamo tre lettere (
pri) e sostituiamole a
., la sequenza di 8 byte diverrà
e's primar che è appunto il testo visualizzato:
though the enterprise's primary mission.

